Recap
In Part 1 we
proposed using Apparance as a text processor and tool automation controller to
build our web-site. So, how exactly
would we go building about this?
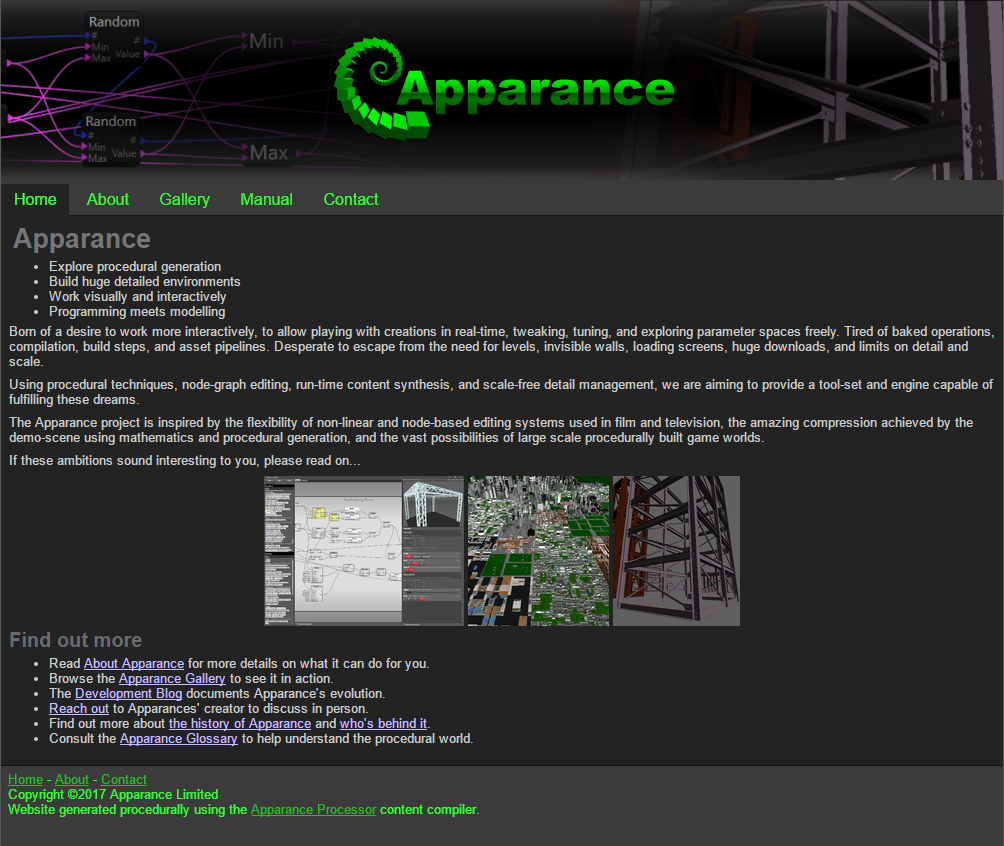
 |
| The Apparance web site prototype. |
Page Structure
Browsing a few basic
web tutorials on how to set up a fairly standard CSS styled HTML page we are
looking at this:
- Title banner and logo
- Site navigation bar
- Page content, different for each page
- Footer with a few common links and note.
 |
| The top-level page generation procedures. |
This provides a
single procedure that can be re-used on each site page, with the page specifics
and customisations passed in as parameters.
For example, here it is used on the homepage.
 |
| All that is needed for a top level, text content based page. |
All that is needed for a page like this is the content source and a couple of constant values.
Title
I wanted the title to
use the Apparance logo, and have a background that hinted at both what you can
make with Apparance, and how you make it.
This is a combination of background image banner and centred logo.
| Title banner background (transparency shown as checker-board) |
| Title logo (transparency shown as checker-board) |
Both of these are
images that are prepared by hand (at the moment) and just need to be copied
across if they are updated or missing, this is handled by the Image Fetch
procedure (see below).
 |
| Header background (CSS) and logo (HTML) generating procedures |
There is a bit of styling to apply the background, and the logo is an image HTML element over the top.
Navigation
The navigation bar
should be a simple row of buttons with hover highlighting and current page
indication. These provide the top-level
site choices, the leftmost one being the main homepage and site entry-point.
 |
| The main navigation bar. Current tab and hover highlighting shown. |
To do this properly,
the idea is to have the items expressed in a simple a way as possible in the
HTML and leave the funky appearance to the CSS.
The best of conventional wisdom points at using an un-ordered list (UL
tag) with list items (LI tag) for each menu option. With the appropriate tagging, this can then
be 'skinned' into a row of buttons using only CSS.
Again, this can be a
single procedure that gets re-used on each page. In fact, some of the pages will require a
second row of buttons to navigate sub-pages (too many pages to have them all in
one row). We can build this procedure
(and the CSS) to support this.
 |
| The bar and button creation procedures. |
 |
| The CSS generation procedure for the navigation bar and buttons. |
The procedure to
generate the CSS is designed to be applied twice, with the menu level as a
parameter. This allows the styling to be
slightly different and provide a raked appearance to the menus as they
transition into each other and the page content.
 |
| Example of a double level navigation bar. |
To get the to show the correct selected page in each place it's used, the page it is on is passed as a
parameter which causes that button to have the selection highlight styling
applied.
Footer
The page footer is
very simple, just a few links and some text.
| Simple page footer |
It is included in
the general page procedure as it appears at the foot of every page.
 |
| Common footer procedure and where it fits in. |
We may need to
include some customisation later so that when on pages it actually links to,
those links are disabled (for neatness).
There are other cool things we could do with the footer later I'm sure.
Content
Markdown
The main part of
every page is the content and comes, for most of them, from external markdown
files. This allows the content to be
written in a form that can be transformed into HTML as well as other forms if
we need (see later). Here is an example
of what the content looks like in raw markdown and on the actual page.
 |
| Markdown source document compared to resulting HTML page output. |
Custom
Some pages warrant
custom generation and rely on special procedures to generate their
content. A good example of this is with
the online user documentation pages I want to include. Here, instead of hand-writing simple textual
descriptions to appear on the Operators manual page, we can build it
automatically from the operator definitions that the editor already dumps out
on start-up (a simple form of user doc that was added ages ago). This is in the following form:
 |
| Source operator description format generated by the editor |
By loading this in
with the file read operator, applying some recursive scanning of the content
(using find and split operators to parse each section), we can generate web
page content for it. With some HTML
table and a sprinkle of CSS magic we can generate fairly good facsimiles of the
actual operators in the editor.
 |
| Resulting operator documentation example |
These have
hover-tips for extra detail where available, such as the internal operator name
and the IO connection descriptions.
There is also a summary section that appears at the top of the page with
links to each section.
 |
| Summary section for the operator documentation |
Code Generation
The page
construction process is broken down into various modular parts, split between
the HTML generation and the CSS generation as well as being split into generic
(re-usable) operations and ones specific to our site or page.
I've found that by
wrapping even the simplest tags with procedures, it keeps the graphs readable,
and also allows for site-wide fixes and additions to any of the HTML or CSS
constructs.
 |
| It's even worth wrapping the simplest of tags. |
Most code output
(CSS or HTML) is actually just text string concatenation, for example, the
heading tag just prepends the opening tag and appends the closing tag:
 |
| The heading procedure, parameterised by level (and ID) |
HTML & CSS
A library of HTML
element procedures and CSS constructs have been accumulated as the site
constructed.
 |
| Reusable HTML and CSS procedures |
The HTML ones are
mainly for the tag types that can be used, with a few attribute types to help
build them. The CSS ones are containers
for the styling of each section, and a load of property helpers. Here you can see them in use on the common
content styling:
 |
| CSS property helpers in use |
Procedures
Some of the
re-usable building blocks, specifically for handling files are described in
more detail here.
Image Fetch
Using the new file
operators, the paths can be prepared, the timestamps checked, and the copy
performed if required. On success we
pass out the relative path to the image file, ready for use in the HTML or CSS
code.
 |
| Image fetching procedures. |
Document Read
The markdown
documents are read in by invoking Pandoc with the source file as a parameter
and accumulating the text output by it to the console stream. If the return value indicates an error we
report a suitable error message.
 |
| Document reading and processing procedures. |
Some additional
document processing is done here to achieve two things:
- Image tags are parsed and used to drive image thumbnail generation, propagate the main file, and replace the image element with the thumbnail and a link to the full image.
- Lists have a little bit of formatting added to turn "Title - Description…" into "Title - Description…" to make the headings stand out a bit more. This is styled and can be updated globally.
Thumbnail Generation
Where image tags are
included in any content the processing step applied on load (if enabled)
generates the thumbnail automatically.
There are a number of things going on here.
 |
| Processing of all image tags in the document using recursion |
- The document is searched (using recursion) for all image tags.
- The tag is parsed and broken open into its constituants.
- The image file is located and propagated to the output folder.
- A name for the thumbnail is generated based on the image name.
- A thumbnail version of the image is generated in the output folder (using Image Magick).
- A new image tag is constructed (around the thumbnail file).
- The image tag is wrapped in a hyperlink tag pointing at the full image.
- The document around the image tag is re-combined.
There is a lot going
on here, but it can all be laid out nicely and the flow of information is clear
from the procedure construction.
Viewing the Results
Now we have this all
up and running, as changes are made to the procedures the top-level page
procedure we are 'viewing' is re-built for us.
This is an HTML page with the required images nearby that can readily be viewed
in a browser.
Live Page
One additional
requirement to be able to see changes in real-time is for us to get the browser
to refresh as pages change. This could
be done with the auto-refresh timer you can add to a web page, but this is
rather crude as it will a) be updating all the time, and b) have to be doing so
rapidly to get a decent response time to changes.
A bit of digging
turned up a lovely little Chrome extension called LivePage. After setting a few options up, you can click
on the icon alongside any page and have it watch the source file for
changes. On detecting one the page is
reloaded.
 |
| LivePage browser extension in Chrome |
It is proving really
good for working interactively and has options to track changes to HTML,
embedded CSS, and even source image files (experimental, but seems good).
Content
By adding a quick
directory watcher feature into the editor I was able to also have generation
happen when the source content (markdown) documents or source images
changed. This nicely rounded off the
editing experience.
Interaction Examples
The best way to see
all this working together is a video, so here you are.
So far this has been
a really fun way to develop the web site, and I'm certainly going to continue
along this vein. I hope you liked this
slightly tangential application of the technology, I expect there will be more
of this sort of thing in the future.